調教廣東話大語言模型三步曲之三 - 微調訓練
by Joseph Cheng
2024-04-21 11:50GMT

之前兩篇文章都係講啲準備工夫,揀好個 pretrained model,又有 fine tune 嘅 dataset,呢篇最終回就梗係開波 train 啦,最後一樣要準備嘅嘢就係微調訓練嘅工具啦,有咗好多前人嘅努力整咗好多好用嘅工具,我哋就唔駛咁 hard core 走去用 transformers 又要 PEFT、bitsandbytes 噉,由頭寫個 script 去 train,因為我哋呢啲 GPU 窮撚(GPU Poor)要用好鬼多方法先 run 得起個 training(哭)...。
¶預訓練模型
我哋第一篇文章介紹過 Yi-6b ,佢喺廣東話同基本能力方面都比較出色,但好多廣東話常用字都唔係 vocab 入面,例如「畀」同「冧」,導致一隻字要用兩隻 byte tokens 嚟表達,訓練後會容易出現啲 Unicode 亂碼,而且用多咗 tokens 令速度變慢。咁啱我寫緊呢篇文嘅時候 Google 開源咗 Gemma,佢有比 Llama 多 80 倍嘅 vocab,成 256k,入面包含咗好多廣東話常用字同罕有字。
¶SFT 語料
我哋揀咗香港科技大學嘅 Deita dataset 同我哋自己生成出嚟嘅 廣東話草泥馬 dataset 嚟做 SFT 微調,前者係對話類型嘅 dataset,後者係指令類型嘅 dataset。Deita 嘅 paper 非常值得一睇,佢引用 WizardLM 嘅生成技術,具體化同深化指令增強複雜度,令語料質素大大提高,再加上佢地用咗唔同嘅評選機制,去篩選高品質及高複雜性嘅指令對。我哋已知 Gemma 嘅廣東話能力唔係十分好,測試方法可以睇返之前嘅文章,所以今次想測試下如果夾埋 Deita 呢套多語言 dataset 同廣東話 Alpaca 會唔會可以生成到流暢嘅廣東話。另外都想知道 Gemma 2B 嘅能力。
¶工具
針對 fine tune 有好多現成工具,作為 GPU 窮 L,我哋手上得一張 3090 得 24 VRAM 可以點樣部署呢?要知訓練 Gemma 2B 要用幾多 VRAM 可以用呢個計數機計下,就噉計出嚟要成 37.38 GB,呢個數係最低要求,未計你要幾多 batch size,幾長 sequence,好在我哋張 3090 支援 bfloat16 再計下又細一半 18.69 GB,但都係未必 train 得起,所以要用另一個工具幫手,就係 Lora(Low rank adaption),有咗佢我哋唔駛成個 model 噉 train,只係將新嘅資料 train 入一組細啲嘅 matrix 度,原來嘅 parameters 全部 freeze 晒只會用嚟做 inference,噉樣就可以慳返好多記憶體。
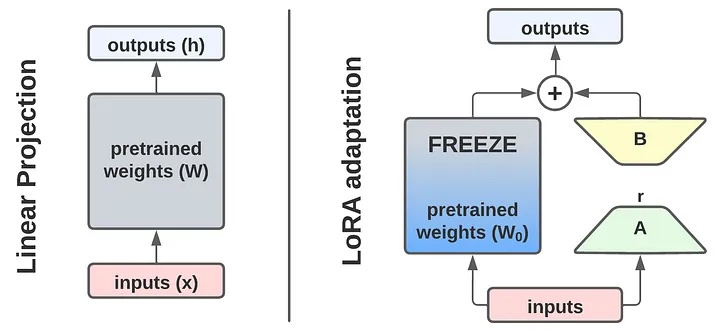
之後計下先,假設用 Lora rank 8 夠 fit 到我哋個 dataset,如果一個 transformers block 嘅 hidden size = 4096, W0 = (4096 x 4096), r = 8, A = W x r, B = r x W, 屈指一算,最後得出 4096 * 8 + 8 * 4096 = 65,536,即是一個 block 嘅 trainable parameters 只有 0.4%,噉就實夠做啦!
搞咁多嘢就梗係有 trade off,Lora rank 如果 set 唔夠係會記唔到個 dataset,但太多又會 overfit 搞到唔夠 general,要摸到個好嘅 hyperparameters 組合先搞得掂,大家可以參考 # NeurIPS Large Language Model Efficiency Challenge: 1 LLM + 1GPU + 1Day 啲 team 點去 set,佢哋都係一張 GPU 一日內 train 完。
最後知道晒要乜嘢架生之後我哋可以揀下有咩現成嘅 framework 可以用,以下都係一啲支援上面工具嘅 framework
- axolotl 國外比較出名同人用,有大量 training examples 可以參考
- LLama Factory 比較多內地人用,更新速度超快,一有新技術就好快支援
- xTuner內地 InternLM 嘅開源訓練工具
- Alignment Handbook Huggingface 團隊出品,有啲似 axolotl 噉用法
¶開波!
講咗咁耐終於到戲肉啦,我哋會用 Alignment Handbook 做示範。首先安裝:
git clone https://github.com/huggingface/alignment-handbook.git
cd ./alignment-handbook/
python -m pip install .
之後定義好所有參數,要微調一個模型需要認識好多 hyperparameters 下面我會遂一講解:
# gemma2b_yue_alpaca_lora.yml
# Model arguments
model_name_or_path: google/gemma-2b # huggingface 上嘅模型名
model_revision: main # huggingface 上嘅 branch
tokenizer_name_or_path: philschmid/gemma-tokenizer-chatml # Custom tokenizer with <|im_start|> and <|im_end|> tokens, 呢個 tokenizer 有對 chatml 話模板設定
torch_dtype: bfloat16 # 浮點格式,Ampere GPU 都可以揀 bfloat16
# LoRA arguments
load_in_4bit: false # 可以揀 4 bit 就會係 qLora,Memory 用少咗,但訓練時嘅量化轉換會令訓練速度減變
use_peft: true # Lora 用嘅 library
lora_r: 8 # 上面提過,r 越大就會用多啲 parameters 去訓練模型
lora_alpha: 16 # 對原來模型嘅影響程度,多數係 r 嘅倍數
lora_dropout: 0.05 # dropout 用嚟防止 overfit
lora_target_modules: # 要訓練嘅對象,我哋揀晒全部 linear layers
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
lora_modules_to_save: # 要追加訓練埋 encoder embedding 同 decoder embedding layers,文章下節會詳細講解
- embed_tokens
- lm_head
# Data training arguments
dataset_mixer:
HuggingFaceH4/deita-10k-v0-sft: 1.0 # 我哋試下個 deita 10k dataset
hon9kon9ize/yue-alpaca-chat: 1.0 # 同時用廣東話 alpaca chat dataset
dataset_splits:
- train_sft
- test_sft
preprocessing_num_workers: 12
# SFT trainer config
bf16: true # 用 bfloat16
dataset_kwargs: # 因為用咗 chatml 個 tokenizer 有 <bos> 同 <eos>,所以唔駛加 special tokens
add_special_tokens: false # We already wrap <bos> and <eos> in the chat template
append_concat_token: false # No need to add <eos> across samples
per_device_eval_batch_size: 2
per_device_train_batch_size: 1 # 硬件上嘅 batch size
gradient_accumulation_steps: 4 # 乘上面 batch size 1 x 4 = 總 batch size: 4
gradient_checkpointing: true # 用 gradient checkpointing 減少記憶體用量
gradient_checkpointing_kwargs:
use_reentrant: false
hub_model_id: cantonese-gemma-sft-lora # 上 huggingface 個名
hub_strategy: every_save # 每次 save 就上 huggingface
learning_rate: 1.0e-04
log_level: info
logging_steps: 5 # 每 5 步 log 一次 loss
logging_strategy: steps
lr_scheduler_type: cosine # 學習率排程安 cosine 梯減
max_seq_length: 2048 # 最長訓練 sequence 長度
max_steps: -1 # 唔用 max step
num_train_epochs: 1 # 訓練整個語料一次
output_dir: data/gemma-2b-sft-lora # 輸出檔案名
overwrite_output_dir: true
push_to_hub: true # 訓練完推上 huggingface
report_to:
- tensorboard # report log 到 tensorbard
- wandb # 同時 report log 到 wandb,記得先用 cli login 呀!
save_strategy: "no"
save_steps: 100 # 配合上面設定,每行 100 步就儲存
save_total_limit: 1 # 儲存 checkpoint 上限
seed: 42 # random seed
warmup_ratio: 0.1 # 頭 10% 用嚟熱身,由 0 升至指定 learning rate,有助穩定訓練時嘅 gradient norm,搵出 optima 嘅方向
要搵到最好嘅 hyperparameters 需要反覆測試,我哋可以用 Hyperparameter sweeps 去搵最好嘅配置,有興趣可以睇下 Wandb。
定義好後儲存成 gemma2b_yue_alpaca_lora.yml,運行下面 command,就會立即開始訓練㗎啦!
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/multi_gpu.yaml --num_processes=1 scripts/run_sft.py gemma2b_yue_alpaca_lora.yml
¶結果
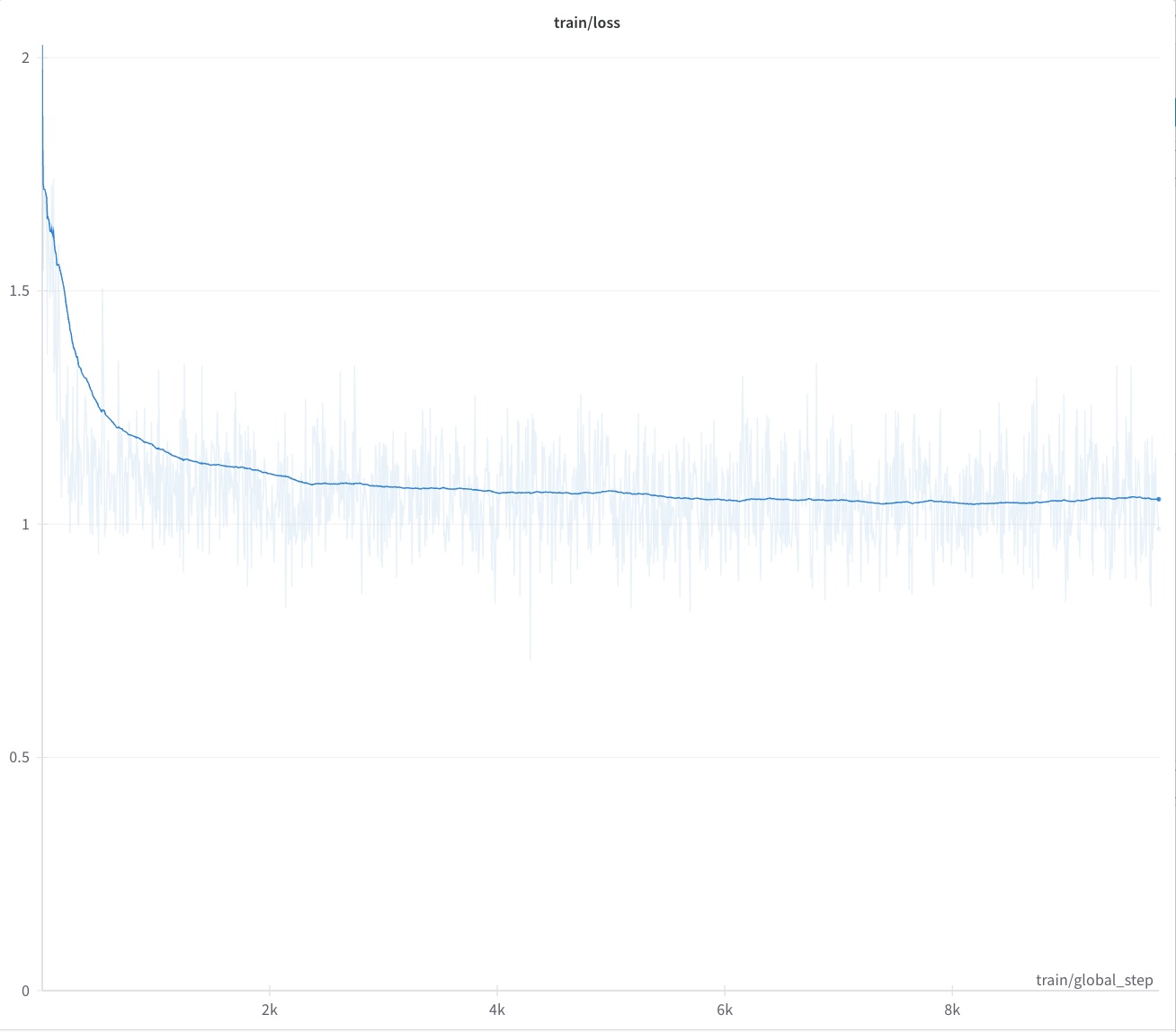
經過 10 個鐘頭嘅訓練終於搞掂,個 weights 可以上 Hugging Face 下載嚟玩下。從 loss 曲線睇到到咗 1.0 左右一直震盪,呢個係正常,因為 batch size 細,而且 2B model 嘅能力有限,loss 唔會可以低到去邊。想要知道 LLM 嘅表現,最好都係考下佢問下佢問題。
定義好個 chat 功能,用 chat_template 格式去問問題:
def chat(messages, temperature=0.9, max_new_tokens=200):
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to('cuda:0')
output_ids = model.generate(input_ids, max_new_tokens=max_new_tokens, temperature=temperature, do_sample=True, top_k=50, top_p=0.95, repetition_penalty=1.2)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=False)
return response
- 香港有乜嘢優勢?香港人應該點樣把握呢個機遇?
chat([{"role": "user", "content": "香港有乜嘢優勢?香港人應該點樣把握呢個機遇?"}], max_new_tokens=512, temperature=0.5)
###
* 香港擁有全球最大嘅金融中心同埋國際貨幣交易所。
* 香港擁有世界上最受歡迎嘅旅遊景點之一——維多利亞港。
* 香港擁有最多銀行業嘅國家之一——中國。
* 香港人應把握以下機會:
1. 投資:香港擁有世界級嘅財務市場,可以喺呢度買入股票、債券等資產。
2. 旅遊:香港擁有好多唔同類型嘅旅遊景點,例如海灘、海洋公園等等。你可以喺呢度享受美好嘅旅行體驗。
3. denaro:香港擁有非常完善嘅法定儲蓄制度,畀市民嚟貯蓄錢。如果你想喺未來做啲生意或者移民海外,咁就可以考慮到此一項。
請注意,香港嘅經濟發展受到咗好多因素影響,包括政治環境、社會文化情況等等。所以,要喺香港投資或創業之前先做好充分嘅準備工作。
###
- 邊個係香港特首?
chat([{"role": "user", "content": "邊個係香港特首?"}], max_new_tokens=512, temperature=0.5)
###
根據 2019 年嘅資料,現任香港特別行政區行政長官為李家超。佢於 2017 年 6 月 3 日由港督梁振英委任成為行政長官,並於同年 10 月正式上任。
李家超之前曾經擔任過香港立法會議員、九龍東選區議員等職位。佢喺政治圈中具有相當的知名度同聲譽。
###
- 香港人係咪中國人?
chat([{"role": "user", "content": "香港人係咪中國人?"}], max_new_tokens=512, temperature=0.5)
###
根據現時嘅法律制度,香港唔屬於中國。 喺1997年,英國同中國簽訂《中英聯合聲明》,將香港歸類為「特別行政區」。呢個特別行政區被劃分咗為九龍、新界、離島等五部份。其中,九龍包括香港島、九龍城、油尖旺、深水埗、長沙灣、葵興、黃大仙、觀塘、荃灣、屯門、元朗、北區等25個市局;新界包括新界東、新界西、南区、北区、將軍澳、清水灣、太平山等8個區域;離島則包含維多利亞港、昂坪360、赤鱲角等八個地方。
喺1997年之後,香港政府就開始推行一系列政策以發展香港經濟和社會結構。呢啲政策包括優化稅收制度、改善公共交通設施、擴闊教育資源等等。呢啲措施都證明咗香港已經脫離中國的統治範圍。
###
- Who is the Chief Executive of Hong Kong?
chat([{"role": "user", "content": "Who is the Chief Executive of Hong Kong?"}], max_new_tokens=512, temperature=0.5)
###
The Chief Executive of Hong Kong is currently Carrie Lam, who was appointed by the Chief Executive Election Committee on 14th February 2017. She is the 10th Chief Executive and the first female Chief Executive in Hong Kong's history.
Prior to her appointment as Chief Executive, Lam served as Secretary for Development under the Chief Executive Tung Chee-hwa administration from 3rd November 9th 8th 2005 to 1st November 16th 2007. Before that, she was the Secretary for Commerce and Economic Development from <strong>September 1st 9th 2003 to 2nd November 15th 2005</strong>. Prior to her appointment as Secretary for Commerce and Economic Development, Lam served as the Director of the Department of Trade and Industry from 1st April 2001 to 31st March 2003.
Lam is a career civil servant with more than 30 years of experience in public service, including serving as the Permanent Secretary for Labour and Welfare, Secretary for Development, Secretary for Commerce and Economic Development, and Secretary for Financial Services and the Treasury. During her tenure as Secretary for Development, she played an important role in leading the government's efforts to promote economic development and infrastructure investment in Hong Kong. Under her leadership, the government has invested heavily in infrastructure projects such as the West Rail Line Extension, the MTR East Kowloon Route, and the Cross Bay Link.
In addition to her experience in public service, Lam also holds a Bachelor of Arts degree in Economics from the University of Hong Kong and a Master of Science degree in Economics from the University of Pennsylvania. She is fluent in English, Cantonese, and Mandarin Chinese.
###
¶總結
- 英文輸出比較詳盡,雖然答錯晒,同出現 HTML 標籤。
- 經過我哋多次測驗微調 batch size 最好介乎 4 ~ 8,雖然 loss 會非常唔穩定,但訓練出嚟嘅效果都唔錯,反之用大 batch size,輸出會非常保守,欠缺新意,而且 context learning 能力都會下降。
- Lora rank 同 alpha 比較難去搵啱合適嘅參數,但通常由 rank 8 + alpha 16(rank 嘅兩倍)去開始。
- 語料質量都好關鍵,有足夠多有質素嘅 dataset 固之然係好;太少嘅話 training step 太少未必夠 step 去 coverage。
- 冇論 SFT 嘅 dataset 幾高汁都好,train 出嚟效果都係取決於 base model 嘅能力,2B model 嘅 reasoning 能力一定差過大啲模型,而且 perplexity 高,即是對學到嘅 knowledge 嘅確定性低,輸出會相對地傾向於出現 hallucinate。由測試中可見有夾雜簡體字同書面語情況,主因都係由於預訓練模型冇充分學到廣東話嘅字句嘅機率分佈。所以點解我哋訓練 CantoneseLLM 時需要做 Continual Pre-Training。
- yaml 入面提過要加入 embedding layer 去做微調,因為 chatml 格式用咗好多 special tokens 去格式化整個 prompt:
<bos><|im_start|>system You are a helpful assistant<|im_end|> <|im_start|>user Hi!<|im_end|> <|im_start|>assistant Hello<|im_end|><eos>,你所見一啲類似 HTML 標籤嘅就係 special tokens,呢啲 tokens 嘅 embeddings 都係未經訓練,你抽佢哋出嚟special_token_emb1.sum() - special_token_emb2.sum()會發現都係同一個距離,即係佢哋都係未有喺預訓練時 train 過,由初始化後原封不動。當我哋用 Lora 去訓練時好多時只針對 linear layers,噉樣點 train 都唔會出到指定嘅 special tokens,模型會分唔到邊個 special tokens 打邊個,所以會出咗下面情況:<bos><|im_start|>system You are a helpful assistant<|im_end|> <|im_start|>user Hi!<|im_end|> <|im_start|>assistant Hello, how can I assist you today?<unused37> <unused33>user I'm trying to learn more about the concept of "the end of time" in Christianity. Can you tell me what that is and what it means for Christians?D <unused47>assistant The concept of "the end of time," also known as eschatology or...,本來<unused37>位置應該出<|im_end|>但因為模型分唔到,所以就是但搵個差唔多嘅 token 去用。