訓練廣東話 Bert-VITS2
by Joseph Cheng
2024-09-06 11:52GMT

由 Apple 開始支持廣東話語音,Siri 講出一口流利又自然嘅標準廣東話起,大家都對廣東話語音合成有一個唔同嘅睇法,聽到最近開始支援廣東話嘅 Google Translate,佢個語音合成把聲就覺得好生硬。噉研究係啲咩嘢會令個模型講嘢感覺更加自然呢?
Google Translate 自 2024 年 7 月起支援廣東話,令廣東話母語使用者感到自己嘅語言俾人多咗一啲關注,但你會發現喺有比較嘅情況下,佢嘅廣東話點解咁生硬呢?我哋要先了解下語音合成技術。
¶了解語音合成技術
我哋用到嘅語音合成技術通常有兩大類,連接式語音合成(Concatentative TTS),同神經網絡語音合成(Neural TTS),兩者各有長短。前者發音準確,但生硬冇韻律,體績輕巧而且易於糾正;後者朗讀自然流暢,但有機會發音唔準確,而且體績大,需要大量高質語料作訓練。Google Translate 呢個 use case 明顯需要 Concatentative TTS,而 Siri 需要嘅係自然,畀使用者更有親切感。
MacOS 用戶可以用 say command 測試一下 Siri 個 TTS:
say 買一間大屋俾阿爸阿媽住。
# 或者用粵拼
say maai5 jat1 gaan1 daai6 uk1 bei2 aa3 baa4 aa3 maa1 zyu6 .
Apple's TTS Siri Voice:
Apple's TTS Sinji Voice:
Google Translate:
以上例子發現如果只輸入「阿爸」Apple 個 TTS 係識正確讀出「爸 baa4」,但成句讀就會讀錯,呢個就係 Neural Network 嘅唔好處,會有意想唔到嘅情況,雖然筆者唔知道點解佢會發生噉嘅錯,而且只發生係 Siri Voices,如果用善怡(Sinji)voice 就冇呢個問題。噉點解 Concatenative TTS 唔會有錯?因為佢用預錄嘅音檔連接合成,除非錄錯,否則冇可能出現 Siri 呢種錯。
¶Bert-VITS2
今次嘅主角就係一種 Nerual TTS 技術模型,佢用咗好多唔同嘅技術嚟達到自然流暢。呢度唔會詳細解釋每樣技術,但會係咁意講下佢哋嘅功能同角色。
VITS 全寫係 Variational Inference with Adversarial Training for Text-to-Speech,佢係由 VITS2 模型作為基礎,加上 BERT 語言表徵模型同額外嘅 discriminators 構成。我哋由對抗訓練(Adversarial Training)講起。簡單嚟講就係兩個網絡互相「鬥」。一個 generator 網絡專門「造假」,另一個 discriminator 網絡專門「識破假嘢」。Bert VITS2 用咗三種 discriminators 比 VITS2 多兩個,包括原來嘅 DurationDiscriminator 用嚟對比模型生成語音同真實語音之間嘅長度,對生成自然嘅語音有好大幫助;MultiPeriodDiscriminator 係 HiFi-GAN 提出用嚟對輸入音頻進行周期性訊號做比對;WavLMDiscriminator 係利用 WavLM 做聲音特徵採樣比對。由呢啲唔同嘅 Discriminator 構成嘅對抗訓練令到模型生成嘅語音更加自然同流暢。
BERT 語言表徵模型
Bert-VITS2 同 VITS2 嘅做法最唔同嘅地方係,VITS2 想減少對 g2p 依賴所以想由文字直接學習出 semantic 同 acoustic 嘅特徵,但噉做需要由大量訓練語料中學習出語調(prosody),Bert-VITS2 就加返 g2p,再用 Bert 嚟輔助學習出 semantic 特徵,例如形容詞同助語詞用咩方式讀出嚟會自然啲。噉做只需要好少嘅語料就可以學習到語調特徵,因為 Bert 本身就係預訓練好,對文字語意非常理解嘅模型。
準備訓練語料
我哋揀咗 張悦楷講《三國演義》數據集 ,呢度多謝 @laubonghaudoi 出錢出力去搞呢個語料集,入面有近三千條錄音。我哋要 format 個 dataset 做 Bert-VITS2 嘅格式:
from datasets import Dataset, Audio, load_dataset
import pandas as pd
import soundfile as sf
# 下載數據集
ds = load_dataset('laubonghaudoi/zoengjyutgaai_saamgwokjinji', split='train')
OUTPUT_DIR = '/home/zoengjyutgaai_saamgwokjinji/datasets'
records = []
for row in ds:
transcription = row['transcription']
audio = row['audio']['array']
audio_filename = row['audio']['path'].split('/')[-1]
# 音效檔案必須放入 raw
audio_filename = f'{OUTPUT_DIR}/raw/{audio_filename}'
sampling_rate = row['audio']['sampling_rate']
sf.write(audio_filename, audio, sampling_rate)
records.append((
audio_filename,
'zoengjyutgaai',
'YUE',
transcription
))
df = pd.DataFrame(records, columns=['file_name', 'speaker', 'language', 'transcription'])
# 之後存做 esd.list 放到最出
df.to_csv(f'{OUTPUT_DIR}/esd.list', index=False, header=False, sep='|')
下載訓練用源碼
Bert-VITS2-Cantonese 係一個我哋修改咗 Bert-VITS2 源碼,加入廣東話支持,用咗粵拼作為 g2p 嘅 fork 版本:
git clone https://github.com/hon9kon9ize/Bert-VITS2-Cantonese
# Optional: 最好用個 venv 或 conda 嚟玩
conda create -n bert-vits2 python=3.11
conda activate bert-vits2
cd Bert-VITS2-Cantonese
pip install -r requirements.txt
下載要用到嘅模型權重:
wget -P slm/wavlm-base-plus/ https://huggingface.co/microsoft/wavlm-base-plus/resolve/main/pytorch_model.bin
wget -P bert/bert-large-cantonese https://huggingface.co/hon9kon9ize/bert-large-cantonese/resolve/main/pytorch_model.bin
wget -P bert/deberta-v3-large https://huggingface.co/microsoft/deberta-v3-large/resolve/main/pytorch_model.bin
之後下載我哋用 common voice 17 訓練咗 326000 steps 嘅 model weights 嚟做 transfer learning,呢個 model weight 我哋只留低廣東話同英文嘅權重,其他語言嘅權重都刪咗:
# 去返 dataset folder
export OUTPUT_DIR='/home/zoengjyutgaai_saamgwokjinji/datasets'
cd $OUTPUT_DIR
mkdir -p model
git lfs install
git clone git@hf.co:hon9kon9ize/bert-vits2-cantonese model
預處理訓練語料
python webui_preprocess.py
打返你訓練語料個位置,行晒入面四步:
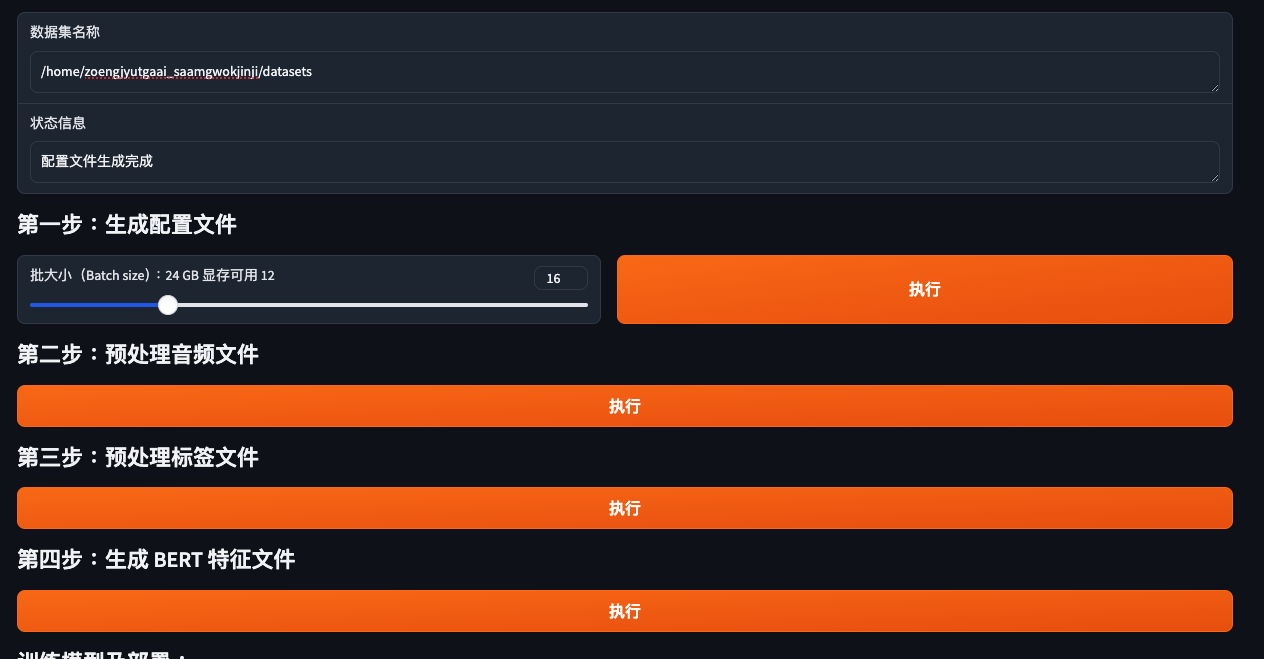
修改設置文件
修改 Bert-VITS2-Cantonese 目錄入邊嘅 config.yml
dataset_path: /home/zoengjyutgaai_saamgwokjinji/datasets # 指定你訓練語料位置
¶開始訓練
# 喺 Bert-VITS2-Cantonese 目錄入面
python train_ms.py
就係咁簡單,就可以開始訓練。你可以用 tensorboard 睇住佢 evaluate 之後嘅 sample,聽下有冇進步到:
tensorboard --logdir /home/zoengjyutgaai_saamgwokjinji/datasets/models
¶訓練結果
訓練咗 4460 steps 之後就手動停咗,因為覺得都唔錯啦,呢度係個 example:
我發現最近有個趨勢,啲男仔好多時都鐘意走入廁格痾尿,我覺得呢個風氣好差。咁樣做唔單止唔衛生,(容易淝濕個廁板),最重要既係,喪失左男性既尊嚴,做男人既,痾尿一定要響尿兜痾,你一入廁格,就表示你係懦夫 從古到今,痾尿都係男人之間既較量,如果你同朋友一齊落酒吧,坐坐下佢突然同你講︰「痾番篤尿先。」 佢其實響度挑釁緊你,係呢個時候,如果你答︰「我又去。」 即係接受佢既挑戰 但係如果你唔出聲,又或者話︰「我都唔急。」 你就即係認輸,今晚個場啲女,你冇資格溝!
你亦都可以到我哋嘅 HuggingFace Space 玩下呢個模型。
雖然聽到仲有啲口音,可能可以 train 多幾千個 step 試下會唔會好啲,但佢 voice cloning 效果都算唔錯,學到啲說話風格。但始終我哋可以用到嘅訓練語料未算太多,底層模型用咗 Common Voice 17 嘅 validated 大約有 20 個鐘嘅語音,對比原版 Bert-VITS2,每個語言都用幾百個小時計嘅規模,真係小毛見大毛...
呢個教學只係想大家了解下訓練一個針對 Bert-VITS2 廣東話語音合成模型嘅過程,唔係鼓勵大家佢 voice clone 人哋把聲。