CantoneseLLM 技術報告
by Joseph Cheng
2024-04-26 11:52GMT

最近我們發佈了 CantoneseLLMChat 廣東話大語言模型,它是一個針對廣東話語言作訓練的開源模型。版本是 preview20240326 版,因為我們內部訓練了多個版本,這個是一個比較穩定而且可以通過內部測試的一個版內,這版本不算是有很好的表現,但它可以作為一個 baseline 為日後的版本作一個參考。這個版本是為了解答兩個問題:
- 多大的語料才足夠令一個大語言模型學會說廣東話?
- 持續預訓練(Continual Pre-Training)對原有基礎模型的影響(Benchmark 方面、及 Catastrophic Forgetting 現像)。
我們借鏡了台灣的 Taiwan LLM 訓練方法,進行兩個階段的訓練,第一階段是用大量的廣東話語料持續預訓練一個基礎模型,第二階段是以對說語料進行微調。
¶持續預訓練(Continual Pre-Training)
持續預訓練階段目的是令已經接受了預訓練的模型學進一步學習更好的語言特徵及知識,有人會試圖跳過這個階段,直接進行微調,甚至 overfitting,來為模型權入知識,這樣得確有一定程度的幫助,但必定會影響模型的泛化能力。有興趣可以看看這個 Reddit 討論。我們期望在這個階段達到的是令模型學會更多廣東話的語言特徵,字詞的關聯性,及語言的結構,亦想它學會更多香港的文化,歷史,及社會知識。
這版本我們用了 01-ai/Yi-6B 的模型作為基礎模,想了解㨂選過程可參考這文章,我們首先要全面了解這個模式對廣東話的表現,及其字典中所覆蓋的廣東話常用字是否足夠,這是在訓練任何語言模型時都要考慮的問題,因為模型的字典是固定的,如果字典中沒有某些字,模型是需要把一個字分折成兩個 token 來處理,這樣會影響模型的表現,而且每一個 token 都有相對應的 embedding,它是一個獨立的向量,很多語言特徵及知識是由這些向量組成的。
我們以粵文維基百科作為 tokenizer 訓練語料,來找出模型字典中的廣東話常用字,並把它們加入到字典中。我們要準備一個 txt 檔案,及安裝 sentencepiece,然後執行以下命令:
pip install sentencepiece
開始訓練一個 BPE tokenizer model:
spm_train --input=raw_corpus.txt \
--bos_id=1 --eos_id=2 --unk_id=0 \
--model_prefix=yue_bpe \
--model_type bpe \
--vocab_size 4800 \
--unk_surface " \342\201\207 " \
--unk_piece "<unk>" \
--bos_piece "<|startoftext|>" \
--eos_piece "<|endoftext|>" \
--pad_piece "<pad>" \
--accept_language zh \
--character_coverage 0.995 \
--num_threads 16 \
--split_digits True \
--byte_fallback True \
--max_sentencepiece_length 4 \
--max_sentence_length 24000
注意,以上的 arguments 都是針對 Yi-6B 模型的,如果你用其他模型,可能要調整一下。這個命令會生成一個 yue_bpe.model 和 yue_bpe.vocab 的文件,然後我們要把這兩個文件放到模型的資料夾中,然後建立一個新的 LLaMaTokenizer。
def expend_tokenizer(tokenizer: LlamaTokenizer, sp_bpe: spm.SentencePieceProcessor):
llama_proto = sp_pb2_model.ModelProto()
llama_proto.ParseFromString(tokenizer.sp_model.serialized_model_proto())
cantonese_proto = sp_pb2_model.ModelProto()
cantonese_proto.ParseFromString(sp_bpe.serialized_model_proto())
llama_proto_tokens_set = set(p.piece for p in llama_proto.pieces)
min_score = llama_proto.pieces[-1].score
new_pieces = []
print(len(llama_proto_tokens_set))
print(f"Before: {len(llama_proto_tokens_set)}")
for p in cantonese_proto.pieces:
piece = p.piece
if piece not in llama_proto_tokens_set:
if is_contain_chinese(piece) and is_hant(piece):
new_pieces.append(piece)
# Add pieces from trash bin to make the vocab divisible by 64 (for most parallelism concerns).
total_pieces = len(llama_proto.pieces) + len(new_pieces)
num_to_add = len(new_pieces) - (total_pieces % 64)
print(f"New pieces: {len(new_pieces)}")
print(f"Num to add: {new_pieces[:num_to_add]}")
for piece in new_pieces[:num_to_add]:
new_p = sp_pb2_model.ModelProto().SentencePiece()
new_p.piece = piece
min_score -= 1
new_p.score = min_score
llama_proto.pieces.append(new_p)
print(f"After: {len(llama_proto.pieces)}")
return llama_proto
tokenizer = LlamaTokenizer.from_pretrained("01-ai/Yi-6B")
sp_bpe = spm.SentencePieceProcessor()
sp_bpe.load(bpe_model) # 之前訓練的 bpe model
llama_proto = expend_tokenizer(tokenizer, sp_bpe) # 這個函數會把新的 pieces 加入到 tokenizer 中
# 以下是參數需要自行調整
with open(output_dir + "/tokenizer.model", "wb") as f:
f.write(llama_proto.SerializeToString())
tokenizer = LlamaTokenizer(vocab_file=output_dir + "/tokenizer.model",
add_bos_token=tokenizer.add_bos_token,
add_eos_token=tokenizer.add_eos_token,
model_max_length=tokenizer.model_max_length,
unk_token=tokenizer.unk_token,
bos_token=tokenizer.bos_token,
eos_token=tokenizer.eos_token,
pad_token=tokenizer.pad_token,
sp_model_kwargs=tokenizer.sp_model_kwargs,
clean_up_tokenization_spaces=tokenizer.clean_up_tokenization_spaces,
legacy=tokenizer.legacy,
)
tokenizer.save_pretrained(output_dir)
print(f"LLaMA tokenizer has been saved to {output_dir}")
得出新的 tokenizer 後,比原有的 tokenizer 多了 1000 多個 token,這些 token 都是廣東話的常用字及組合字,我們把它們加入到模型的字典中,這樣模型就可以處理這些字了。這個擴展是針對單個字元,但可以見到出現了一些組合字元,它們可以令模型輸出的字數增加,因一組字詞只需花費一個 token,但多了不一定好,我們要衡量擴展的字詞太多會使模型的訓練參數加大,而且如在語料中的字頻太少也會令 token 訓練不足。
常用字包括:
- 喺
- 嘅
- 噉
- 冧
...
- 我哋
- 佢哋
- 就係
- 林鄭
...
Tokenizer 擴展後我們必須為模型的 Embedding Layer 進行大少調整,來配合新增的 tokens。
def noisy_mean_initialization(embed_weight: torch.Tensor, num_new_tokens: int):
embedding_dim = embed_weight.size(1)
avg_weight = embed_weight[:-num_new_tokens].mean(dim=0, keepdim=True)
noise_weight = torch.empty_like(avg_weight[-num_new_tokens:])
noise_weight.normal_(mean=0, std=(1.0 / math.sqrt(embedding_dim)))
embed_weight[-num_new_tokens:] = avg_weight + noise_weight
def resize_embedding_layer(model: "PreTrainedModel", tokenizer: "PreTrainedTokenizer") -> None:
r"""
Resize token embeddings.
"""
current_embedding_size = model.get_input_embeddings().weight.size(0)
if len(tokenizer) > current_embedding_size:
if not isinstance(model.get_output_embeddings(), torch.nn.Linear):
print(
"Current model does not support resizing token embeddings.")
return
model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=64)
new_embedding_size = model.get_input_embeddings().weight.size(0)
num_new_tokens = new_embedding_size - current_embedding_size
noisy_mean_initialization(
model.get_input_embeddings().weight.data, num_new_tokens)
noisy_mean_initialization(
model.get_output_embeddings().weight.data, num_new_tokens)
print("Resized token embeddings from {} to {}.".format(
current_embedding_size, new_embedding_size))
model = AutoModelForCausalLM.from_pretrained("01-ai/Yi-6B")
resize_embedding_layer(model, tokenizer)
# Resized token embeddings from 64000 to 65088
調整後可以看到 Embedding Layer 大小由原來的 64000 增加至 65088,要注意 pad_to_multiple_of=64 是為了多張 GPU 作平衡訓練時 layer 可以被 64 整除來分配到不同顯示卡上,所以在 config.json 中 vocab size 不一定會和 tokenizer 的 vocab size 一致。
完成 tokenizer 和 embedding layer 的調整後,可以正式進入 CPT 的階段。我們可參考 HuggingFace 的 Alignment Handbook 中 GPT2 的 CPT 訓練設置,這是一全參數訓練 recipe。訓練語料用的 dataset 需要有一個 text 欄位。而 batch size 和 learning rate 是最關鍵的超參數,我們以 Hyperparameter Sweeps 得到 batch size 需要 64 到 128 才可以有效令 loss 穩定下降。 learning rate 我們選擇了非常保守的 5.0e-5,來避免訓練後會有 Catastrophic Forgetting 的問題,但這點我們未經嚴格的測試來證實,而且這是一個複雜而且未有有效解決方案的問題,有興趣可以參考一下這篇 paper。
預訓練語料
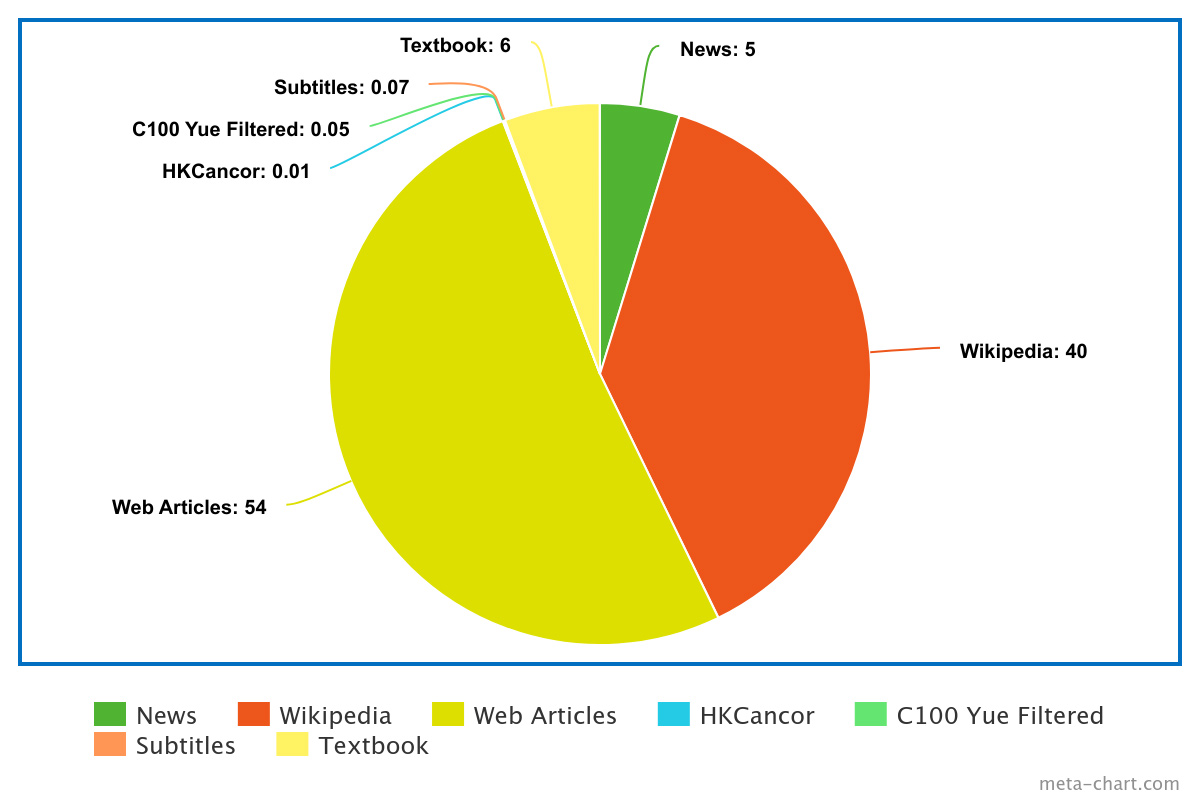
這部分真的說來慚愧,我們可以用作持續預訓練的 token 量只有 2 億左右,而 Yi-6B 是用了 3.1 兆的 tokens 作預訓練,即是大約佔原來的 0.0067%,但這是我們作為一個小小 Community 能力內可搜集到的規模。語料來源如下:
- 粵文維基百科,夾雜英文和非粵語中文
- RTHK News 用了 Bart 模型作廣東話翻譯
- C100 中篩選出的廣東話句子,內有大量和粵文維基百科重複的文字,必須先去重(Dedup)
- 網路文章,多以 Blogs 文章為主
- 廣東話 Textbook,參考 Textbooks is All You Need生成出來的合成語料
- 網上可以下載到的廣東話語料 HKCanor
- 字幕,由網上找到不同字幕組的公開字幕
如早前文章所指,廣東話是低資源語言(Low-Resource Language),無論在質還是在量要追上英文或簡體中文都可能是 0.0067% 甚或至更大的差距。大家也是繁體中文,隔岸台灣可以做到為什麼香港不可以呢?台灣有非常好的寫作風氣,在文字創作上是和香港是「蚊髀同牛髀」的差別,你可以從 Common Crawl 中找出 1.2M 條繁體中文字串,但廣東話只有 17 萬條。另外廣東話在香港是極少用在書寫用途上,反之台灣可以用官方文稿,教學材料等有高質素的文本作為語料一部分。
Textbooks 是一種文字語料生成方法,借助現有的大語言模型,把少量的文字片段給它們轉化成詳盡的教學型式的材料。這個方式不是主要為了增加語料量,而是為了提供高質的內容令語音模式更容易學會文字之間的關聯及知識。但它成了我們在語料不足問題上一個解決方法。我們把它上載到 HuggingFace 連帶生成的方法。
訓練過程用了一張 A100(80GB) 訓練了 1 個 epoch,大概花了 1 天時間,最後的 loss 是 2.1,這個 loss 是不是很高。
¶微調
語料上用了 Chat Markup Language (ChatML) 的格式,作了少許優化:
<|im_start|><|System|>
You are a helpful AI assistant<|im_end|><|Human|>
Hi<|im_end|><|im_start|><|Assistant|>
Hello, anything I can help you?<|im_end|>
這格式是針對多輪對話場景,如 ChatGPT 可根據先前對話內容作答問題都是用上了相似格式。
參考了 Yi 模型預留在 vocab 中的 special tokens,明顯在設計時已考慮到微調任務的需求,如:
<|System|>
<|Human|>
<|Assistant|>
雖然 System 和 <|System|> 在 tokenize 後都是只佔一個 token 量,但我們還是選用了 <|System|> 不辜負設計者一番心機。
訓練詳情和早前文章相約,混合了 Yue Alpaca 和 Deita ,再加上數十條自我身份的訓練對答和數千條 OpenAssistant 語料,語料混合了多種語言的好處能使模型學會就使用者提問時的語言來作回覆,而且只要非常少量就可以令模型學會用不同語言回答問題,可參考這份研究。
超參數設置上都是着眼於 batch size 和 learning rate 上,8 個 batch size 訓練結果比較自然及保有較大多樣性,而 Lora 配置都是參考大多數 NeurIPS Large Language Model Efficiency Challenge: 1 LLM + 1GPU + 1Day中優勝者的:
- Lora Rank: 128
- Lora Alpha: 256(多數是 Rank 的一倍)
- Lora Dropout: 0.05
- Lora Modules: 全 Linear Layers
¶評測
由以下表格可以見 CantoneseLLM 對比原來的 Yi-6B 在 Open LLM Leaderboard 上的綜合評分下降了一個點子,主要是 MMLU 和 HellaSwag 表現大幅下跌有關。HellaSwag 是英文常識推理(Commonsense NLI)評測;MMLU (Massive Multitask Language Understanding) 是知識和理解能力的評測。就這個現象我們的假設是加入新的廣東話語言作持續預訓練時,必然會對原有的知識和語言能力產生影響,由其是以上兩個 benchmarks 都是以英語和美國的知識作評測。GSM8K 是一個小學數學問題集,數學能力提升發在微調後的模型是平常會發生的,因為大多微調語料中數學相關的資料比例一般都較多。
| model | Avg | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|
| hon9kon9ize/CantoneseLLMChat-preview20240326 | 53.1 | 52.56 | 69.05 | 59.19 | 41.87 | 70.32 | 25.63 |
| 01-ai/Yi-6B | 54.02 | 55.55 | 76.42 | 63.85 | 41.86 | 73.8 | 12.66 |
¶不足及限制
因為有很多知識都可能是來自原有的預訓練模型中的中文知識,很多時會出現廣東話夾雜書面語的情況:
User: 咩嘢係狼人殺?
Assistant: 狼人殺係一種多人回合策略遊戲,通常有 12 至 18 名玩家參與。玩家分為兩組:狼人同村民。狼人係狼人,佢哋嘅目標係要殺死村民,而村民嘅目標係要找出狼人並將佢哋處決。狼人同村民都有特殊能力,例如狼人可以隱藏自己嘅身份,而村民可以通過投票來處決狼人。狼人殺遊戲通常需要 30 至 45 分鐘才能完成。
同樣原因,廣東話和英文的知識會有差異,以下例子是我們 CPT 階段中「香港特首」識個知識沒有足夠數量去更新原有模型的舊知識,但重複測試相同問題,有時會可以正確回答,這現象證明了它有學到新的知識,在 decoding 時會注入一些隨機數,有時候可能在新舊知識的機率之間游走。
User: Who is the chef executive of Hong Kong
Assistant: The current Chief Executive of Hong Kong is Carrie Lam.
User: 邊個係香港特首?
Assistant: 現任香港特區特別行政長官嘅李家超
¶總結
觀察結果可以看出現在預訓練訓練的規模是可以達到一個程度的廣東話流暢度,在一些 formal 語氣的對話它的表現是可以接受的,但如果是角色扮演就略嫌未夠地道,這是很易理解的,從預訓練語料的組成分佈可以看出,新聞、網路文章及維基百科佔了大部分,而對話類型的句子寥寥可數。 另外持續預訓練(Continual Pre-Training)對於原有模型能力的影響是非常有限,而且是不可完全避免的。
很多人會疑問這東西做出來有什麼用?GPT-4 不是好好的,比你這個玩意強不知多少倍。在我看來我們是出於學習的心態,和看見到廣東話可以在這個由大語言模型浪潮中走出低資源語言的曙光。GPT-4 或 Gemini Pro 這些頂級模型都具備不錯的廣東話能力,但對比起它們的英語或簡體中文能力還是差距甚遠。而且我們很相信有一天大語言模型是開源社群主導的,而不是落在幾家大企業手上的生財工具。
這個模型可以由我們手中訓練出來都歸功於開源項目團體的成果,不論是開源模型又或是工具,可以讓平民玩家訓練到一個像模像樣的東西。這個版本有很多問題,在我們看來不是由於技術不足,最大原因是廣東話本身是低資源語言,我們用機器翻譯及語料合成等方法是治標不治本,質素受模型能力所限,香港本身不是沒有好的廣東話寫手,但他們的文章不是放在社交媒體上就是放 Medium 或 Patron,很難可以收集得到。
Mozilla 的 Common Voice 令我們多了很多高質的廣東話語音語料,加上多個開源項目出現,令有興趣想嘗試語言合成或語音辨識的朋友可以有「料」可練。這是個良性循環,越多人進入這範疇就越多人會作出貢獻,甚至有人出錢請人上載語音到 Common Voice。同樣地 LLM 要有一個可給他人容易進入的門檻才可以有這個正向循環。
大語言模型(Large Language Model)出現會極大地改變人類的語言,不需多久很多文字都是大部分由人工智能來編寫,我們需要花費一整天去打的文件,它們可以不消一會就跟隨你的指令漂亮地完成。廣東話在當中會成為一個怎樣的存在?